About the digital collection
The digitization of this collection and the creation of this website was done as part of a partnership with the McGill Library and the Groupe de recherche multidisciplinaire de Montréal sur les livres anciens (UQAM) in support of their Social Sciences and Humanities Research Council of Canada funded project to create the Catalogue raisonné pour les Livres d’Heures des XVe et XVIe siècles conservés au Québec. The catalogue was followed by an exhibition at the Montreal Museum of Fine Arts from 4 September 2018 – 6 January 2019 titled Resplendent Illuminations: Books of Hours from the 13th to the 16th Century in Quebec Collections curated by Hilliard Goldfarb (MMFA), Brenda Dunn-Lardeau (UQAM), Richard Virr (McGill).
Digital Collection
This site was created as means of experimenting with Wax and IIIF. You can see the backend here https://github.com/sarahseverson/wax-bofh
What is Wax?
Wax is a minimal computing (minicomp) project led by Marii Nyröp. It relies on Jekyll, IIIF, Leaflet IIIF, Rake, ElasticLunr, and IIIF_S3, and builds upon work by Peter Binkley, David Newbury, and Alex Gil.
Wax is an extensible workflow for producing scholarly exhibitions with minimal computing principles.
It is comprised of a few Ruby gems, some customizable UI components, and (hopefully soon!) a lot of documentation and recipes for creating, deploying, and maintaining digital exhibitions.
The exhibition sites created by Wax are static.
This means they consist of flat HTML, CSS, and JavaScript files that don’t need to communicate in a complex way back to a server. This makes them cheaper, safer, and generally easier to maintain—as long as you’re willing to learn some new skills.
The skills needed to create Wax sites are agnostic.
This means they are largely transferable for use in other digital projects. ‘Learning Wax’ does not mean learning how to use a platform. It involves learning the fundamentals of web development, data management, and plain text editing while leveraging a few great open source libraries and frameworks along the way.
Wax keeps the collection presentation separate from the collection data.
The Wax workflow starts with making standardized image files and metadata records and builds around them, handling canonical information, scholarly content, and site styling differently and deliberately. This makes it easier for you or others to reuse and reimagine your collection data in other contexts.
So what does Wax look like?
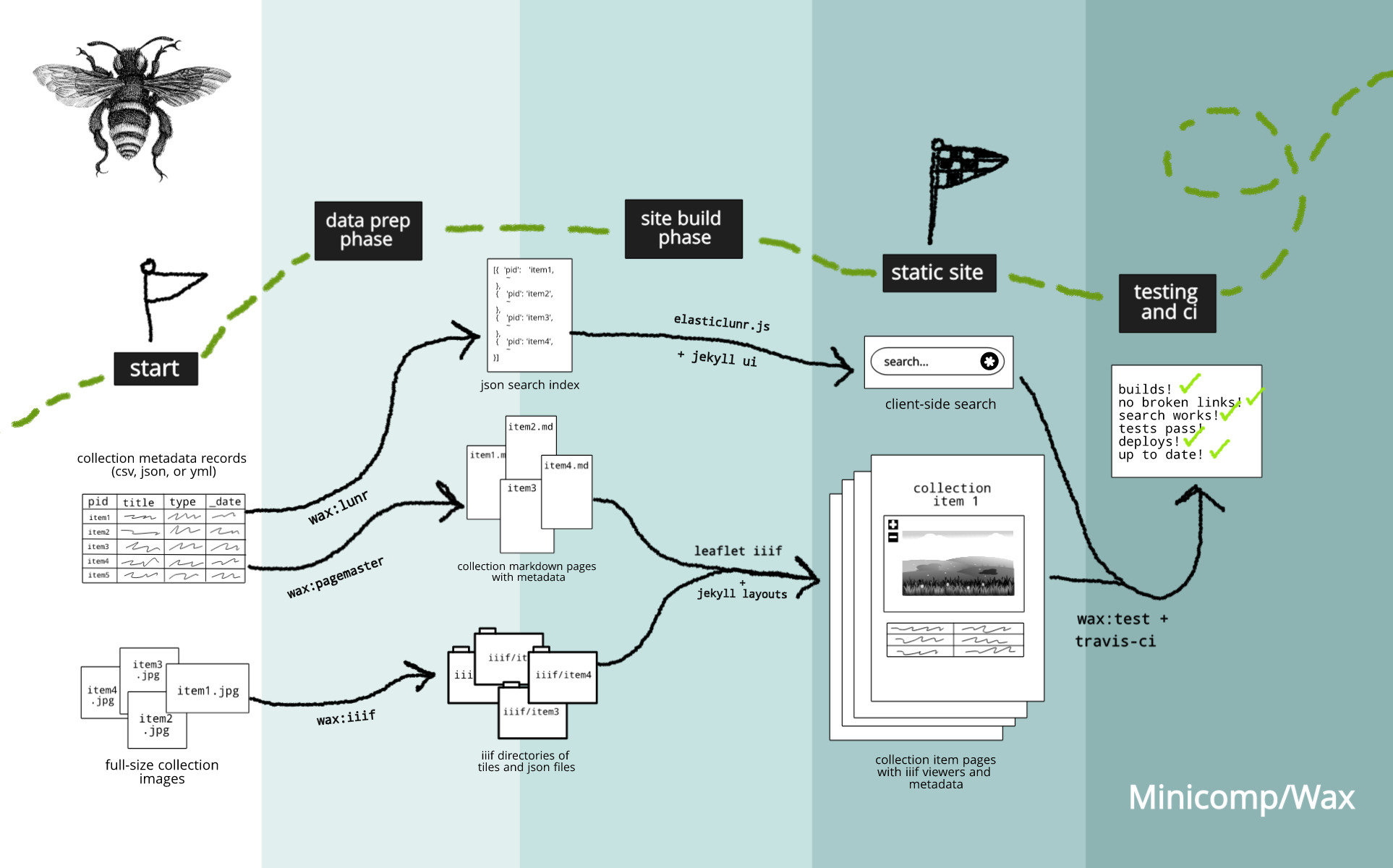
Below is a diagram to give you a zoomed-out view. In summary, you create a file of metadata records for your collection (in CSV, YAML, or JSON format), organize your collection image files, and put both in a Jekyll site folder. After updating your configuration, you run a few command line task to prepare the data and metadata for use by the Jekyll site. Then Jekyll uses special layouts and Wax components to build the exhibition and spits them out as static pages ready to host.
From there, you can run tests on your site to catch errors and decide where and how to put it online with greater flexibility.